What Do We Actually Mean When We Talk About Privacy In Blockchain Networks (And Why Is It Hard To Achieve)?


Part 1/3 in our series on privacy in blockchain networks. Thanks to Raghav (LongHash Ventures) and Lisa (Aztec) for helping with the review! A special mention to Niklas and Olli for all the early discussions that inspired this piece.
The views and assumptions underlying this piece:
Some privacy in blockchain networks is a must-have, not a nice-to-have
The current transparent nature of blockchains is a big blocker to wider adoption
Different users and use cases will require different levels of privacy. Not all problems need to be solved with the same tool.
Do Individual Users Care About Privacy?
Yes, but some more than others.
Everyone cares about privacy to some degree and we all make implicit assumptions about privacy in our daily lives. For example, when writing a message in a company Slack group you assume that only your coworkers can see the messages. Similarly, many are OK with the credit card company or bank being able to monitor their transactions but wouldn’t want to broadcast their transaction history to the rest of the world.
Corporations have additional reasons to care about privacy (competitive, security, and regulatory) and typically a higher willingness to pay for it compared to individual users.
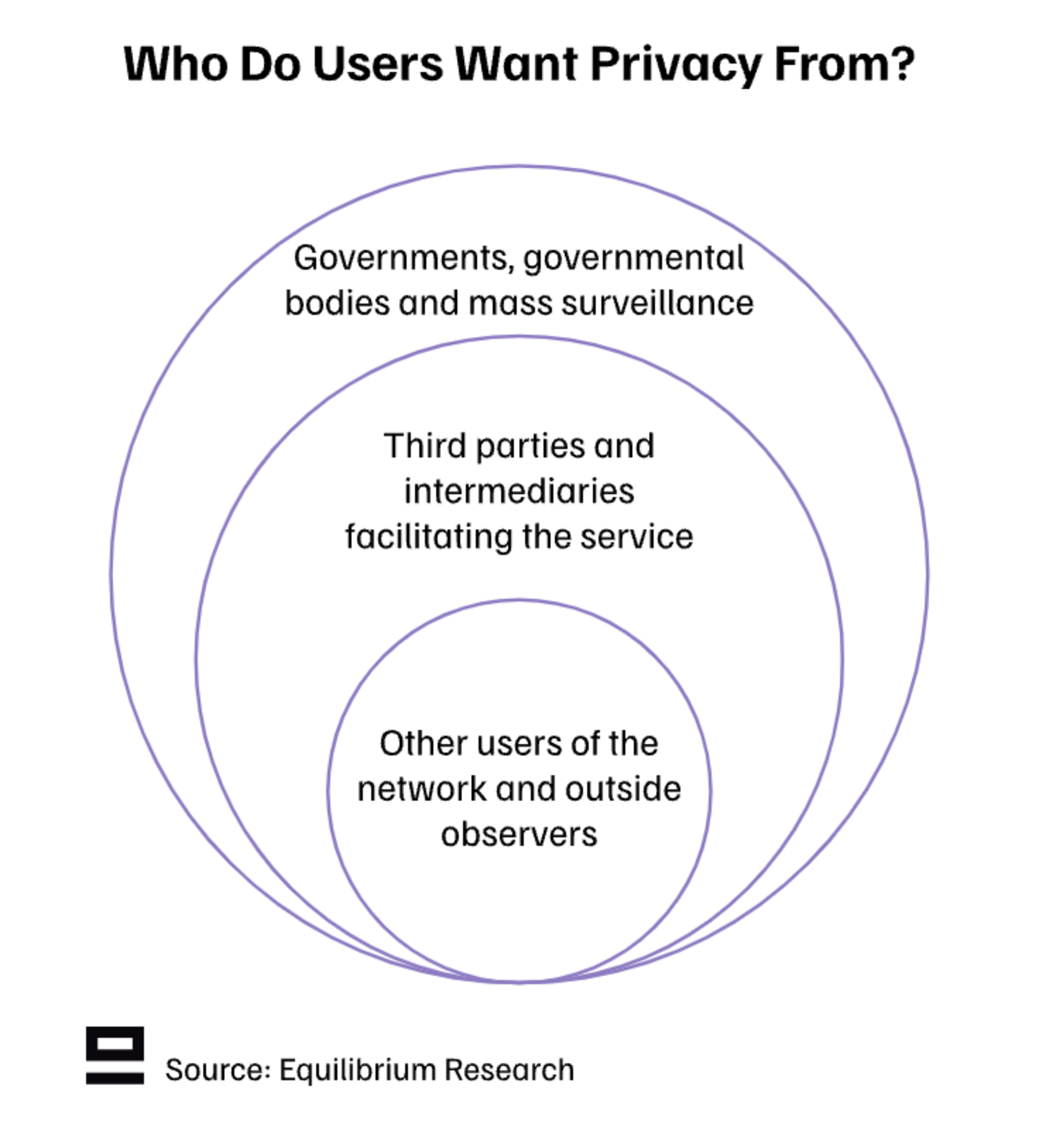
Another important question is: Who do users want privacy from?
Other users of the network and outside observers
Third parties and intermediaries facilitating the service
Governments, governmental bodies, and mass surveillance
The first one is an absolute must for most use cases and is already achievable in blockchain networks today if we accept weaker guarantees (more about this further down). The second one is what we as an industry are working towards to give more control to users and avoid companies with commercial models to leverage our data without permission. The third one - privacy from governments and governmental bodies - is the trickiest from a regulatory and political standpoint.
How Do We Define “Privacy”?
Privacy is not secrecy. A private matter is something one doesn't want the whole world to know, but a secret matter is something one doesn't want anybody to know. Privacy is the power to selectively reveal oneself to the world - A Cypherpunk’s Manifesto
Privacy is a complex subject that covers several separate (but related) topics like data sovereignty (individual ownership of data), cryptography, etc. In addition, people typically use the term quite loosely in different contexts without clear definitions, making it difficult to reason about. Terms such as confidentiality (what) and anonymity (who) are often used interchangeably with privacy, even though both are just a subset of privacy features to aspire towards.
Some key questions concerning privacy are:
What can be revealed and to whom if desired?
Who has the power to reveal information?
What must be revealed and to whom for the system to function?
What guarantees are there that whatever is private today will remain so tomorrow?
Based on these questions, we could sum it up into one sentence:
Privacy is about the user (owner of the data) having control over what data is shared, with whom, and under what terms along with strong guarantees that what is programmed to be private stays so.
Do We Need New Terminology?
Considering the above - is “privacy” a bad term for what we are trying to achieve? Maybe, maybe not. It depends on how you approach it.
On the one hand, the term “privacy” seems quite binary (something is either private or not), but as we highlighted above it’s much more nuanced than that. Different things can be private (input, output, program interacted with, etc), something might be private to one person but public to another, and there is a range of trust assumptions behind different privacy solutions. In addition, the term has a negative connotation which can derail the discussion from the actual topic.
On the other hand, “privacy” is a well-known term with existing mind share. Introducing new terminology can be confusing, especially if there is no consensus around which new term should be used. Attempting to waltz around the topic by using an alternative term also seems somewhat disingenuous and we should be able to speak about things as they are.
As protocol engineers and builders of blockchain networks, looking at things from a new perspective can help us detect new problems or surface gaps in current solutions. Alternative terms such as information flow control (used in the wider privacy literature) or programmable disclosures (our suggestion) perhaps better capture the nuance. Information may be private to some but public to others and it is up to the users to decide what information is shared with whom.
However, we’ll stick to the term privacy in this post to avoid unnecessary confusion.
How Does Privacy In Web2 Differ From Blockchain Networks?
Most internet users are familiar with web2 “privacy”. Our data is encrypted during transit (up to 95% of all traffic today) and shielded from other users, but shared with trusted intermediaries and service providers. In other words, the “privacy” (from other users) comes from trusting an intermediary.
This approach gives some control to the user with whom to share their data beyond the service provider. However, it puts a lot of trust (directly or indirectly) into the service provider to keep data secure and handle it properly. In addition, limited guarantees and little transparency around how data is used means users can only hope service providers behave as they claim (reputation-based model).
Blockchain networks aim to reduce reliance on intermediaries and provide stronger guarantees by moving from a reputation-based model to economic or cryptographic guarantees. However, the distributed model also imposes new challenges, particularly for privacy. Nodes need to sync and reach consensus about the current state of the network, which is relatively easy when all data is transparent and shared amongst all nodes (status quo). This becomes significantly more difficult when we start to encrypt data - a primary reason why most blockchain networks are transparent today.

Why Is Privacy In Blockchain Networks Hard To Achieve?
There are two ways to achieve privacy for blockchain networks: Trusted (intermediated) or Trust-Minimized (non-intermediated) privacy.
Both are challenging, but for different reasons (ideological vs technical). Trusted privacy is more readily available but has weaker guarantees and requires sacrificing some of the ideology of blockchains by relying on centralized actors and intermediaries. Trust-minimized privacy can give much stronger guarantees and ensure users stay in control of their data but is more difficult from both a technical and political aspect (how to stay compliant with current regulations).
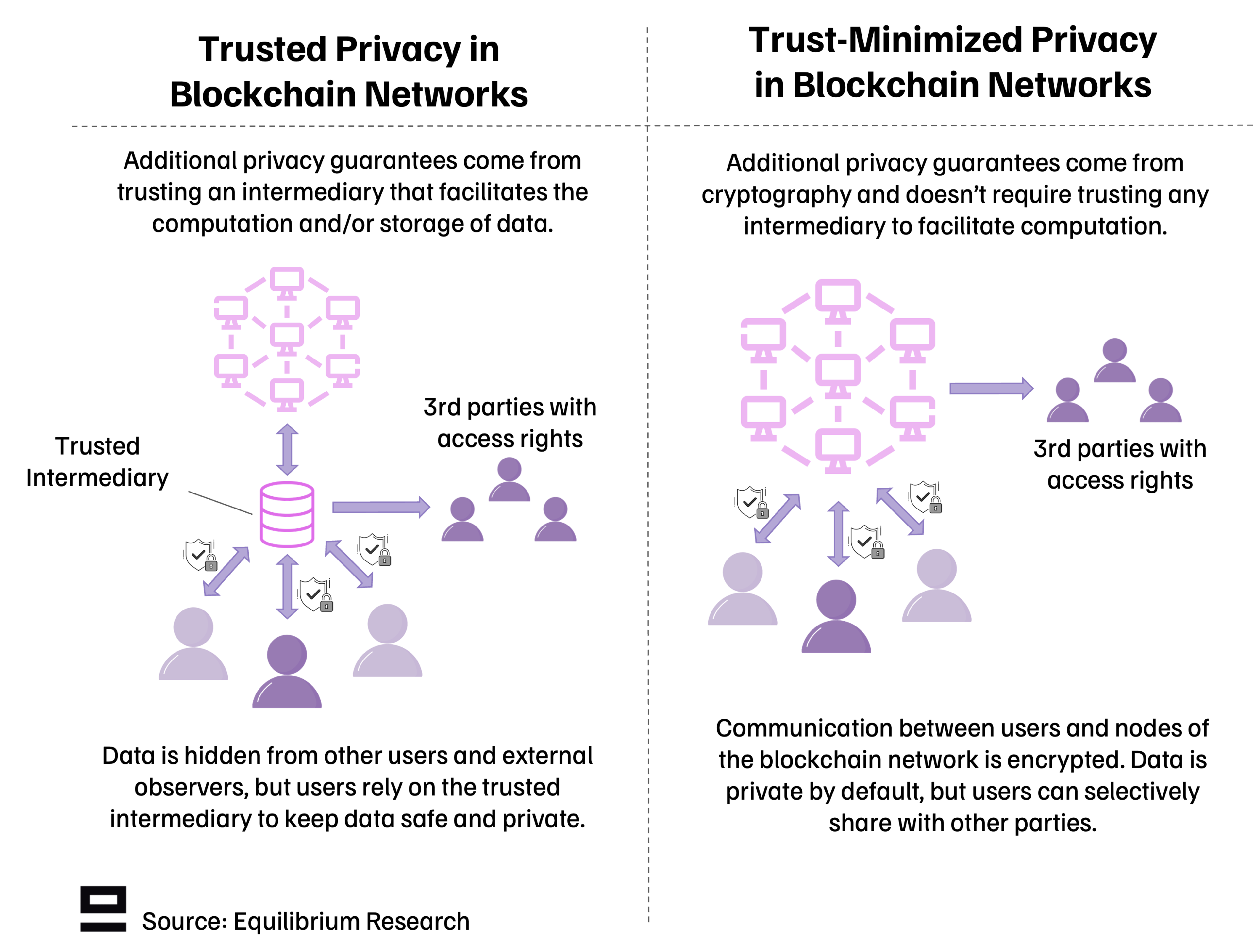
Trusted Privacy In Blockchain Networks
The trusted approach looks quite similar to web2-style privacy in that it can achieve privacy from other users but requires trusting a third party or intermediary to facilitate it. It’s not as technically demanding, making it a pragmatic choice for projects that require some privacy guarantees today but are cost-sensitive and have lower-value transactions. An example of this is web3 social protocols (such as Lens network), which put more emphasis on performance and practicality than the hardness of privacy guarantees.
A simple approach is using a validium where a data availability committee (DAC) holds the current state and users trust the DAC operators to keep that state private and update it as needed. Another example is Solana’s token extension, which achieves confidentiality for payments (hiding account balances and transactions) using ZKPs but allows appointing a trusted third party with auditing rights to ensure regulatory compliance.
We’d argue that this model can extend the current web2 paradigm where you solely trust an intermediary to honor the rules. With blockchains, the pure trust-based model can be combined with some additional guarantees (economic or cryptographic) that the intermediaries will behave as expected, or at least increase the incentive to do so.
There are also hybrid solutions where a trust-minimized solution relies on a centralized component to improve cost, UX, or performance. Examples in this category include outsourcing the proving for private ZKPs to a single prover, or an FHE network where a centralized intermediary holds the decryption key.
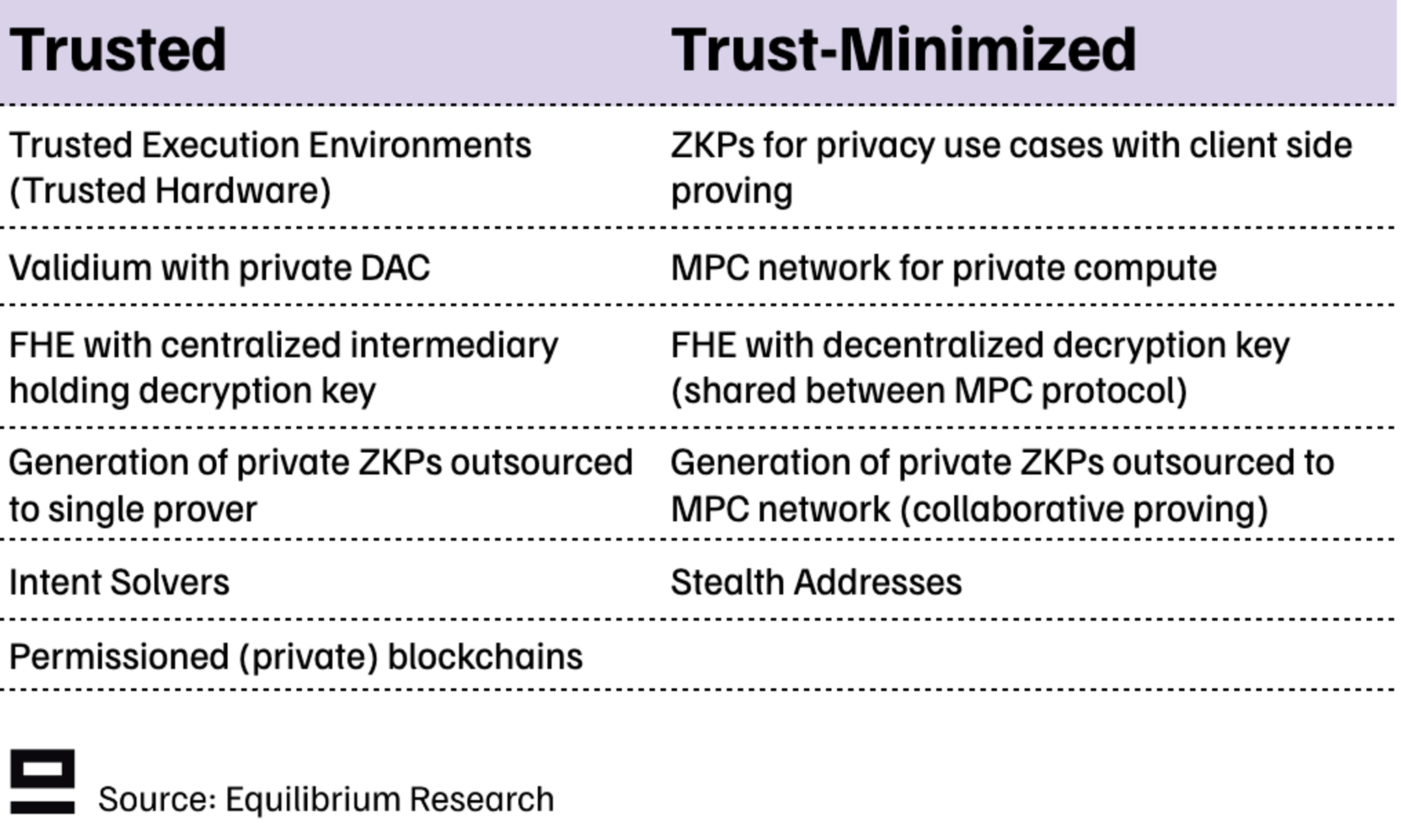
(We include permissioned blockchains in the trusted category, but all other solutions relate to permissionless blockchains).
Trust-Minimized Privacy In Blockchain Networks
The trust-minimized approach avoids having a single point of failure through a trusted intermediary which can give stronger guarantees. However, it’s much harder to implement from a technical standpoint. In most cases, it requires a combination of modern cryptography solutions and structural changes such as using a different account structure.
The existing solutions are mainly around specialized use cases, such as:
Financial: Private transfers, payments, and swaps aim to hide the identity, input, and/or output (who sent what, how much, and to whom). Tradeoffs between different solutions include single- vs multi-asset shielded pools and how much is private. Examples here include Zcash, Namada, and Penumbra.
Identity: Privacy is a non-negotiable for any solution that requires us to connect our off-chain identity to our on-chain identity or attempt to store identity documents on-chain. There are several attempts by the private sector (such as Proof of Passport and Holonym) along with increasing interest by governments to support privacy-preserving digital identity solutions.
Governance: The idea of private on-chain voting is to hide who voted what and keep the total tally private until the end of the vote so that it doesn’t influence the voting decision of any individual. The graph below lists some examples with varying features and trust assumptions:
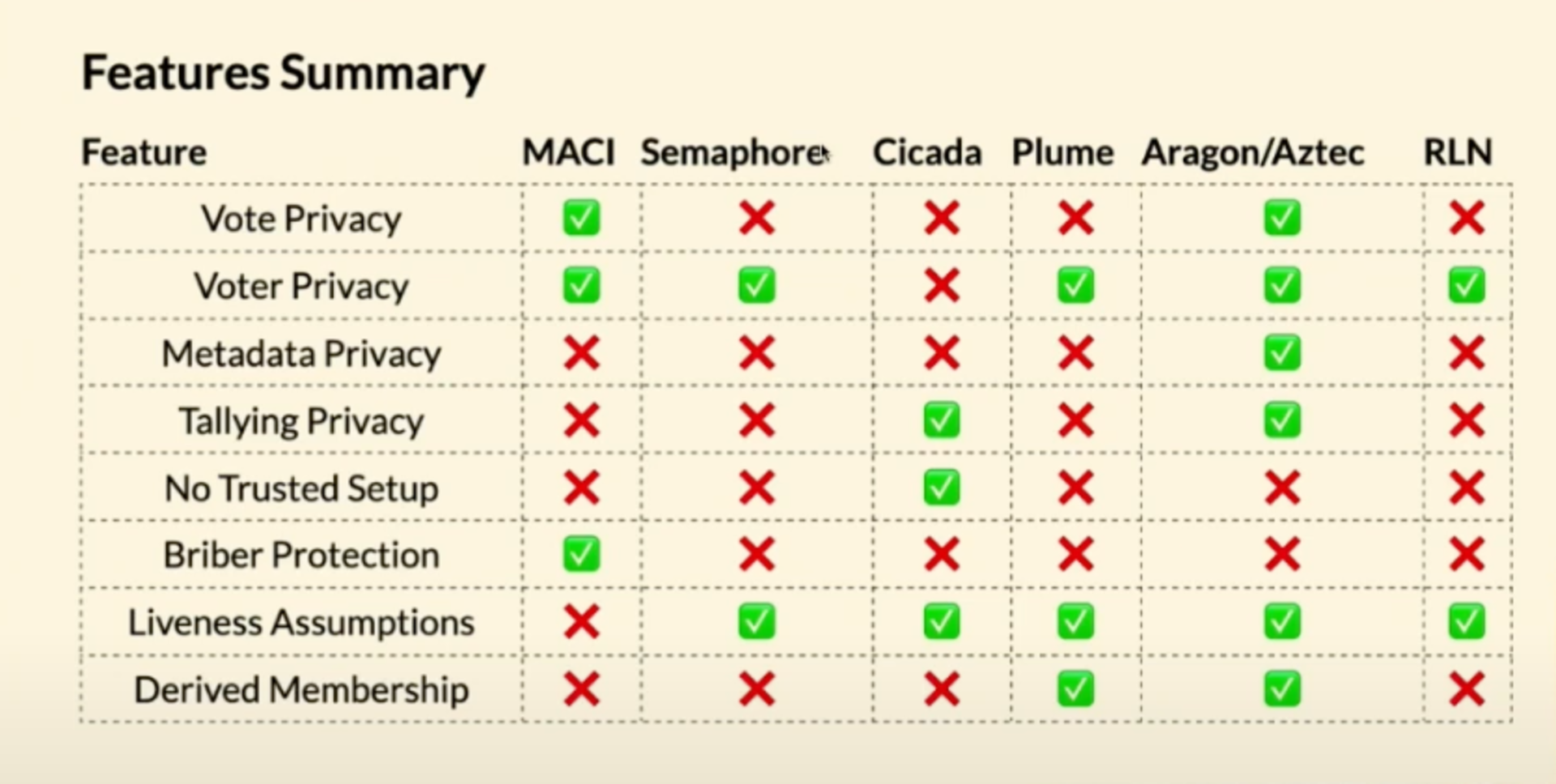
Overview of some existing solutions (source)
Many use cases, however, rely on shared state and it gets a lot more challenging when we try to extend trust-minimized privacy to these general-purpose use cases.
Another thing to note is that while the specialized use cases (payments, voting, identity, etc) might work well in isolation, they require users to move between shielded sets (trust zones) for different use cases. This is sub-optimal as most information is leaked when moving in and out of a shielded set.
Hence, the goal should be to enable privacy for general-purpose computation (all use cases, including those that require shared state), expand the shielded set, and add granular access management controls (expressivity).
How Can We Evaluate Different Solutions?
While the end goal is clear, the road to get there is long. In the meantime, we need frameworks to evaluate the current solutions and what tradeoffs they make. We believe the tradeoff space can be split into three broad categories:
1. What Is Private - Different types of privacy that relate to blockchains:
Private inputs (messages)
Private outputs (state changes)
Private counterparties
Users
Function
Program
The more boxes a solution can tick, the better. Ideally, you would have all of them, but this often requires making some tradeoffs. The difference between function and program privacy is that some systems allow for hiding which function was called (for example which bidding logic the user used), but still reveal the program the user interacted with. Program privacy is a stricter form of this, where all function calls are private along with the program interacted with. This category is also where the discussion around anonymity (who) vs confidentiality (what) falls.
It's important to note that the user has the option to selectively disclose some (or all) of these to certain parties, but if none of them are private by default then the user doesn't have that option.
2. Programmability - What can you use the privacy for?
This category focuses on the programmability of private computation and where its limitations are:
Can you compute over encrypted data? Is there any composability between private programs?
Can private and public states interact in any way? What are the limitations and tradeoffs of this?
What limits are there to how complex programs you can have (gas limits, expressivity, etc)?
As mentioned earlier, many applications (in the real world) require some shared state, which is difficult to achieve in a trust-minimized manner. There is a lot of ongoing work and research in this area to help us move from application-specific privacy solutions that only require local state (e.g. payments), to general-purpose programmable privacy with shared state.
Programmability also relates to having granular tools to selectively disclose certain information and revoke access if needed (for example when an employee resigns, we want to ensure that they don’t have access to company-specific or other sensitive information anymore)
3. Strength of Privacy Guarantees - How reliable is the privacy?
The core question is: How certain can we be that whatever is private today will remain so in the future (forward privacy) and what are the guarantees backing this?
This includes things such as:
What information (if any) does the user need to share with a trusted third party or intermediary? What guarantees are there that the intermediary will behave as expected?
How big is the shielded set? (Multichain > Network (L1/L2) > Application > Single Asset)
What are the risks of censorship? (Application vs Base-layer privacy)
Is the proof system quantum proof?
Does the proof system require a trusted setup? If yes, how many participants did it have?
Does the system have privacy as default or are there other incentives to maximize the number of interactions within the shielded set?
As we can see above, this category includes both technical questions (e.g. which proving scheme one chooses) and design-based questions (e.g. adding incentives that increase the size of the shielded set).
How Does This Tradeoff Framework Map To The Four Questions Presented At The Beginning Of The Post?
What can be revealed and to whom if desired? This question relates to what is private and programmability. If all information is public by default, then the only choice users have related to privacy is whether to participate in the network or not. We need privacy by default to have the option to disclose (at minimum privacy from other users/external observers). Programmability can be represented as granular disclosure rules, i.e. to whom, when, what, and how information is revealed (and revoked).
Who has the power to reveal information? This is mostly related to the strength of privacy guarantees and is strongest when only the user has the power to share information (trust-minimized privacy).
What must be revealed and to whom for the system to function? Primarily relates to programmability. Ideally, you need to reveal as little information as possible while still being able to compute over a shared state, have composability between different programs, and be able to build new trust relationships. In practice, this is not the case (today at least) and some tradeoffs need to be made.
Zooming out for a second beyond blockchains, ZKPs could provide a paradigm shift to this aspect of privacy as they enable us to prove something is true without having to reveal excess information. For example, when renting an apartment, we need to prove to the prospective landlord that we have sufficient income to make rental payments. Today this requires us to send our entire bank statement which gives away a lot of additional information. In the future, this trust relationship might instead be built on the foundation of a succinct ZKP.
What guarantees are there that whatever is private today will remain so tomorrow? The notion of “forward privacy” is mostly related to the strength of the privacy guarantees. Larger shielded sets will help with this and make it harder for outside observers to extract information. Putting less trust in intermediaries can help, but not necessarily as even if users are in full control of their data their keys might leak, data could be unintentionally revealed, or revealed data could be copied. This area remains relatively unexplored and under-studied but will increase in importance as privacy in blockchain networks becomes more widely adopted.
Summary
Ultimately, it comes down to who should have control over what data to share - the users or the intermediaries. Blockchains attempt to increase individual sovereignty, but it’s a challenging fight since ultimately control is power, and power struggles are messy. This ties into the regulatory aspect and compliance as well - a big reason why non-intermediated or trust-minimized privacy will be challenging (even if we solve the technical hurdles).
Today, the discussion is broadly centered around the privacy of financial use cases (payments, transfers, swaps, etc) - partly because that’s where most adoption is. However, we’d argue that non-financial use cases matter equally, if not more, than the financialized ones and they don’t have the same loaded pretense. Games that require private inputs or state (poker, battleship, etc) or identity solutions where the individual wants to keep their original document safe can act as powerful incentives to normalize privacy in blockchain networks. There is also the option to have different levels of privacy within the same application for different transactions or to reveal some information if certain conditions are met. Most of these areas remain under-explored today.
In an ideal world, users have full expressivity of what is private and to whom, in addition to strong guarantees that what is programmed to be private stays so. We’ll take a closer look at the different technologies enabling this and the tradeoffs between them in part 2 of our privacy series.
The transition towards trust-minimized, private general-purpose compute on blockchains will be long and difficult, but worth it in the end.
Continue reading

July 10, 2026
Harvest now, forge at Q-day: the quantum clock is already running for blockchains
We reviewed the node implementations of the 36 largest blockchains. Two have any post-quantum code; none protect consensus. Why exposed public keys make the quantum threat a today problem, not a Q-day one.

April 21, 2026
ZAIR: Zero-Knowledge Selective Disclosure for Zcash Notes
Imagine proving you hold Zcash without revealing which note, how much, or anything else. That's no longer hypothetical. Here's how we built the first end-to-end selective disclosure tool for Sapling and Orchard

April 9, 2026
Scaling distributed systems: Eiger and Equilibrium Labs unite
we're excited to announce that Eiger and Equilibrium Labs are merging to form Equilibrium —a unified team dedicated to advancing the infrastructure that powers the decentralized web.

May 28, 2025
State of Verifiable Inference & Future Directions
Verifiable inference enables proving the correct model and weights were used, and that inputs/outputs were not tampered with. This post covers different approaches to achieve verifiable inference, teams working on this problem, and future directions.

March 25, 2025
Introducing Our Entrepreneur in Residence (EIR) Program
After 6+ years of building core blockchain infrastructure across most ecosystems and incubating ventures like ZkCloud, we're looking for ambitious pre-founders with whom to collaborate closely.

March 10, 2025
From Speculation to Utility: Next Steps For Onchain Lending Markets
Despite its promises, onchain lending still mostly caters to crypto-natives and provides little utility besides speculation. This post explores a path to gradually move to more productive use cases, low-hanging fruit, and challenges we might face.

February 18, 2025
Can Blockchains And Cryptography Solve The Authenticity Challenge?
As gen-AI models improve, it's becoming increasingly difficult to differentiate between AI- and human-generated content. This piece dives into whether cryptography and blockchains can solve the authenticity challenge and help restore trust on the Internet

February 6, 2025
Vertical Integration for both Ethereum and ETH the Asset
In recent months, lackadaisical price action and usage growing on other L1/L2s has driven a discussion on what Ethereum’s role and the value of ETH, the asset is long-term.

January 29, 2025
Equilibrium: Building and Funding Core Infrastructure For The Decentralized Web
Combining Labs (our R&D studio) and Ventures (our early-stage venture fund) under one unified brand, Equilibrium, enables us to provide more comprehensive support to early-stage builders and double down on our core mission of building the decentralized web

November 28, 2024
20 Predictions For 2025
For the first time, we are publishing our annual predictions for what will happen by the end of next year and where the industry is headed. Joint work between the two arms of Equilibrium - Engineering and Ventures.

November 7, 2024
9 + 1 Open Problems In The Privacy Space
In the third (and final) part of our privacy series, we explore nine open engineering problems in the blockchain privacy space in addition to touching on the social/regulatory challenges.

October 15, 2024
Aleo Mainnet Launch: Reflecting On The Journey So Far, Our Contributions And Path Ahead
Equilibrium started working with Aleo back in 2020 when ZKPs were still mostly a theoretical concept and programmable privacy in blockchains was in its infancy. Following Aleo's mainnet launch, we reflect on our journey and highlight key contributions.

August 12, 2024
Do All Roads Lead To MPC? Exploring The End-Game For Privacy Infrastructure
This post argues that the end-game for privacy infra falls back to the trust assumptions of MPC, if we want to avoid single points of failure. We explore the maturity of MPC & its trust assumptions, highlight alternative approaches, and compare tradeoffs.

August 1, 2024
Working on Aptos: Insights into Mutation Testing and Specification Assurance

July 23, 2024
Equilibrium brings Move to Polkadot

July 23, 2024
Releasing Lumina.rs - Directly verify Celestia in your browser
We're excited to release Lumina. Go to https://lumina.rs/ and run a Celestia light node in the browser. By running Lumina you synchronize with the network, sample data availability, directly verify correctness and contribute to the network health

April 9, 2024
Will ZK Eat The Modular Stack?
Modularity enables faster experimentation along the tradeoff-frontier, wheras ZK provides stronger guarantees. While both of these are interesting to study on their own, this post explores the cross-over between the two.

January 16, 2024
Nebula for Soroban: Simplifying Contract Execution

January 16, 2024
Equilibrium is taking over responsibility for Beerus StarkNet Light Client

December 14, 2023
Enhancing Rust RPC Client and Nodes for Celestia Network

December 11, 2023
Introducing the MoveVM Substrate Pallet

October 23, 2023
Unveiling the Zcash UniFFI Library

October 5, 2023
Overview of Privacy Blockchains & Deep Dive Of Aleo
Programmable privacy in blockchains is an emergent theme. This post covers what privacy in blockchains entail, why most blockchains today are still transparent and more. We also provide a deepdive into Aleo - one of the pioneers of programmable privacy!

September 18, 2023
Securing cross-chain communication from Ethereum to the Internet Computer with an on-chain Light Client

September 4, 2023
Elusiv: Bringing Privacy To Solana

July 31, 2023
Engineers thoughts: Fireblocks SI partnership

July 25, 2023
Introducing OpEVM: The Next Generation Optimistic EVM Rollup

June 7, 2023
Equilibrium Becomes the First Accredited Systems Integrator for Fireblocks
March 12, 2023
2022 Year In Review
If you’re reading this, you already know that 2022 was a tumultuous year for the blockchain industry, and we see little value in rehashing it. But you probably also agree with us that despite many challenges, there’s been a tremendous amount of progress.

May 31, 2022
Testing the Zcash Network
In early March of 2021, a small team from Equilibrium applied for a grant to build a network test suite for Zcash nodes we named Ziggurat.

June 30, 2021
Connecting Rust and IPFS
A Rust implementation of the InterPlanetary FileSystem for high performance or resource constrained environments. Includes a blockstore, a libp2p integration which includes DHT contentdiscovery and pubsub support, and HTTP API bindings.
June 13, 2021
Rebranding Equilibrium
A look back at how we put together the Equilibrium 2.0 brand over four months in 2021 and found ourselves in brutalist digital zen gardens.
January 20, 2021
2021 Year In Review
It's been quite a year in the blockchain sphere. It's also been quite a year for Equilibrium and I thought I'd recap everything that has happened in the company with a "Year In Review" post.