

In part 1 of our series on the intersection of AI and crypto, we explored how blockchain and cryptography can work together to help distinguish between human (“real”) and AI-generated content (“fake”), thereby reintroducing trust on the internet.
In part 2, we cover verifiable inference, different approaches to achieve it, teams working on this problem, and future directions. While verifiable inference sometimes goes hand in hand with privacy-preserving inference, this post will primarily focus on the verifiability aspect.
Thanks to Jack Min (Prime Intellect), Dante (EZKL), Wenfeng and Hang (Phala) for discussions related to the post and/or help with the review!
AI Inference 101
Inference is the act of calling an existing AI model with a prompt (input). The model applies the input to its pre-existing settings (weights), assesses different predictions, and ranks them according to their fit to the model. The best prediction (answer) based on the input is fed back to the user.
There are two main variations of inference, based on where the compute happens:
Local = The user runs the model on their own hardware (consumer hardware or edge device) or hardware they control (local server), without involving any third parties.
Local inference is natively privacy-preserving since prompts, model weights, and user data don’t leave the consumer’s device. However, it also requires some technical ability to set up, which adds friction. In addition, the hardware requirements can be quite restrictive, especially for larger and more complex models.
Outsourced = The model is hosted by a third-party service provider (trusted or untrusted), which receives the user’s input (prompt), does the computation (inference), and sends a response (output) back to the user.
Trusted - The hosting party is known and has their reputation at stake (e.g. OpenAI or Google). Sufficient incentive for the service provider to act honestly (i.e. use the right model and not interfere with the request). Particularly for more complex models (LLMs, image generation models, etc), the majority of users leverage this method of inference today.
Untrusted - The service provider doesn’t have a pre-existing reputation or the user doesn’t even know who the compute provider is (e.g. a node in a decentralized inference network or a random server in Romania). Requires some additional proof of integrity to ensure that the service provider is honest.
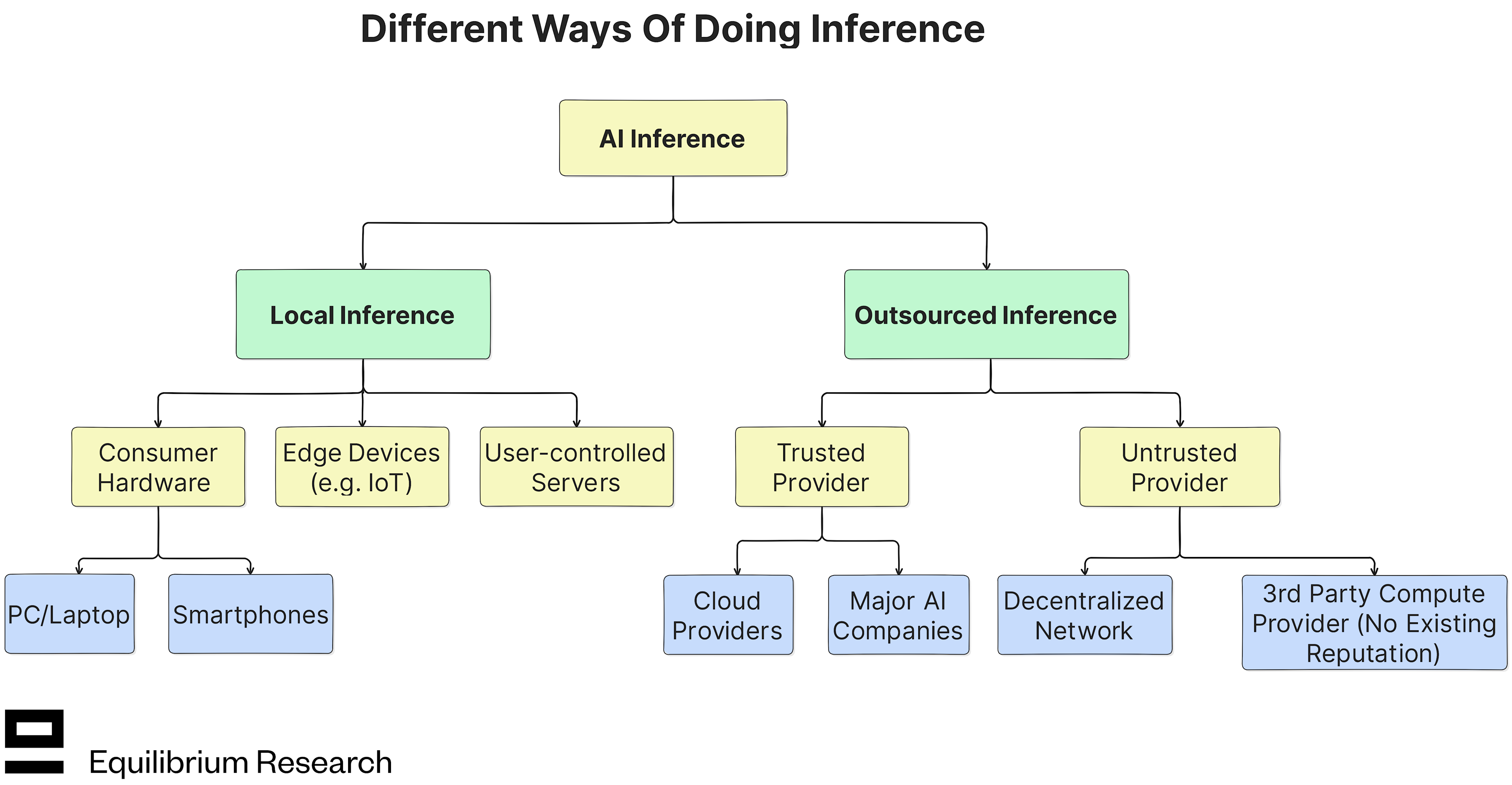
In reality, the notion of “trusted” and “untrusted” is both subjective and more of a spectrum than a binary choice. However, the core idea is that trusted providers have a reputational stake, whereas the untrusted service providers have no or little reputational stake (much less to lose for acting maliciously).
Verifiable Inference
Verifiable inference enables proving that integrity was retained during the inference process, more specifically that:
The correct model and weights were used
Inputs (prompt) and outputs (answer) were not tampered with
The two main benefits of verifiable inference are:
Increasing Traceability: As AI becomes more intertwined with our decision-making, there might be a need to prove that the answer came from a specific model and that inputs/outputs weren’t tampered with during the process (for legal and compliance purposes). This has some similarities to the black box in airplanes, which is used after an accident to determine what went wrong and whether the crew and pilots were at fault.
Relevant for: High-impact use cases, where the user (e.g. doctor or security analyst) wants to limit their personal liability if something goes wrong later.
High-potential use cases: Medicine, finance, security, defense
Increasing Trust: When outsourcing inference to untrusted parties (whether centralized or decentralized), users cannot blindly trust the operator to be honest. Instead, additional guarantees of integrity are needed.
Relevant for: Highly adversarial environments that need stronger guarantees rather than just blindly trusting the operator. In this case, verifiable inference is a prerequisite for the interaction to work.
High-potential use cases: Integrating AI/ML to blockchain-based applications and outsourcing inference to untrusted servers or decentralized inference networks.
However, the relative importance of these benefits varies depending on how you do inference:
Local inference primarily requires verifiability for post-inference traceability and auditability for legal and compliance reasons.
Trusted outsourced primarily requires verifiability for post-inference traceability and auditability for legal and compliance reasons, similarly to local inference. However, there might also be value in the service provider proving to the user that they are honoring their commitment (in addition to reputational trust), at least at random intervals.
Untrusted outsourced primarily requires verifiability to build trust and enable the interaction to happen in the first place, given there is no reputation to fall back on. Decentralized inference networks fall under this umbrella.
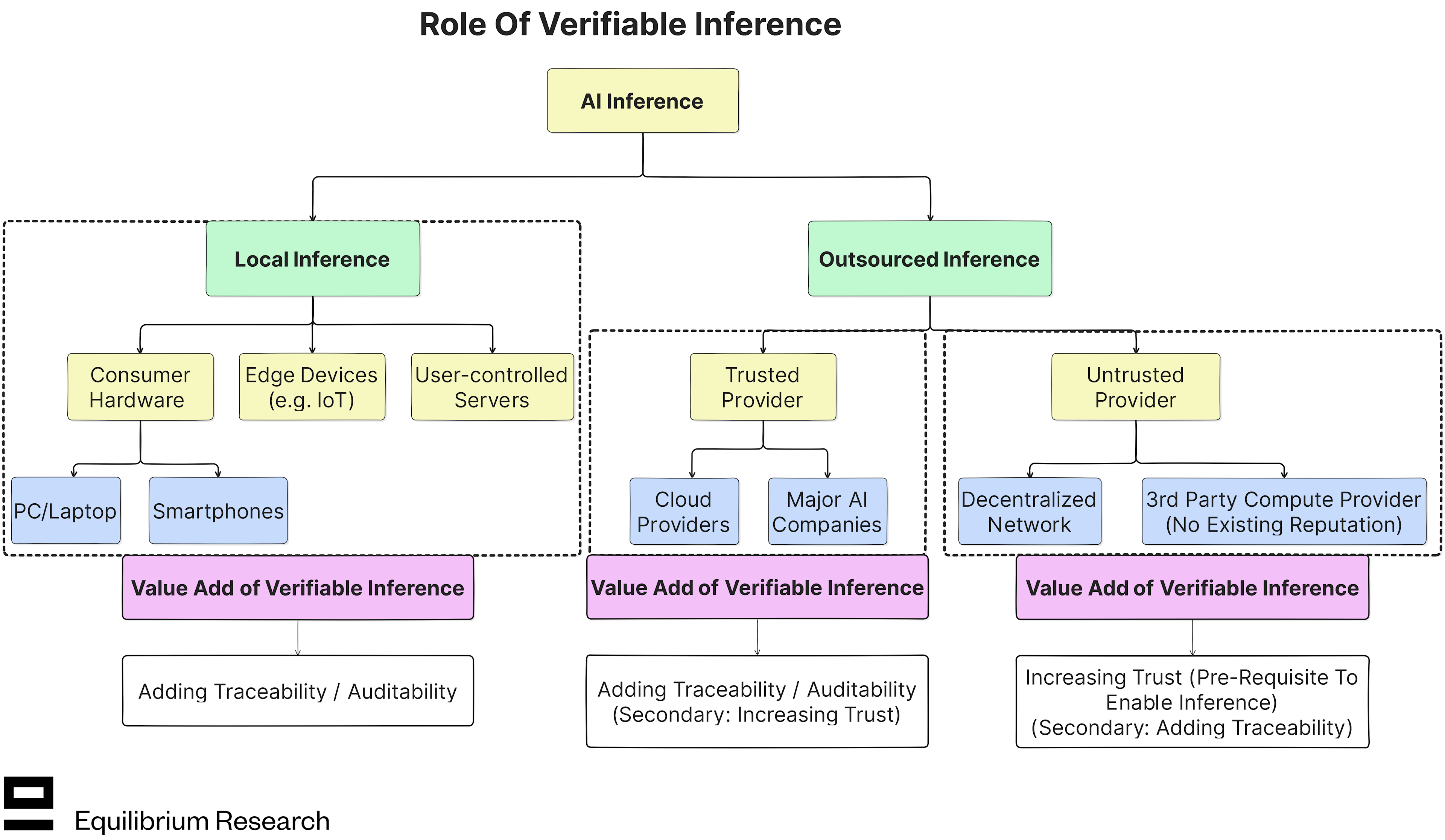
The primary value of verifiable inference differs depending on where the compute takes place
Verifiable Inference x Blockchains
In a blockchain context, verifiable inference is mainly relevant to increasing the expressivity of onchain applications, enforcing onchain agents, and enabling decentralized inference networks:
Increasing Expressivity Of Onchain Applications: Most blockchains are inefficient (overhead from re-execution, networking, etc) and have limited compute resources (blockspace). This limits the type of applications developers can build, as even a simple linear regression (let alone more complex AI/ML models) would be prohibitively expensive to run on-chain. Delegating this work off-chain solves the scalability issue, but the protocols require strong guarantees that the task was computed correctly. That’s where verifiable inference comes into the picture. One example where we’re already seeing this today is:
Smart DeFi = DeFi protocols integrating off-chain components and AI/ML models to improve their product, something we’re already seeing with an increasing number of protocols (both new and existing). This can increase capital efficiency (e.g. automated LP rebalancing based on historical trends and volatility), reduce risk (e.g. credit risk models for lending protocols), or introduce new features (e.g. automating investing based on specific signals).
Onchain Agents: The first use cases of onchain agents have been relatively simple, such as autonomous Twitter bots (which often have a token attached to them or control a cryptowallet with some funds). However, as onchain agents evolve into more productive use cases, verifiable inference becomes an important piece of validating that a particular task was fulfilled according to pre-agreed rules. Only after this can a payment for the service be triggered.
Decentralized Inference Networks (DIN): Blockchains are notoriously good at creating global markets and finding the cheapest available resources (hardware and energy). With respect to inference, this means tapping into latent GPUs and energy sources, which can lead to significant cost savings for the end-user, along with additional guarantees around censorship resistance and liveness. However, given the highly adversarial nature of blockchains, it’s unreasonable to assume that no one will cheat or purely trust the reputation of these node-operators (little to no reputational risk). Hence, verifiable inference is a prerequisite for decentralized inference to work and a necessary requirement to build trust between the users and compute providers.

Ways To Achieve Verifiable Inference
Integrity during inference can be verified through multiple approaches, including zero-knowledge proofs (ZKPs), trusted execution environments (TEEs), hashing, optimistic verification (relying on honest watchers), and random sampling. These offer different tradeoffs between cost, performance, strength of guarantees, usability, etc. Below is a summary of each approach, along with main use cases, benefits, drawbacks, and open problems:
Zero-Knowledge Proofs (zkML)
ZKPs are a software-based approach to verifiable inference, where the AI/ML model is converted into ZK circuits to enable proving the execution trace. This can either be done manually for each model or by using a compiler that generalizes this step for multiple different models. The latter is what most companies working on zkML are focusing on, with the aim to support a wide range of models and standards.
If the model runs locally and the user generates the ZK proof on their own device (client-side proving), then ZK-based inference can also provide some privacy guarantees. This is what Rarimo, for example, is working on. However, most projects utilize server-side proving due to the complexity and high compute requirements.
Main Use Cases
Inference that requires strong guarantees (mission-critical parts of the product) and isn’t as time-sensitive. The value added through strong guarantees of correct execution is worth more than the proving overhead cost.
Proving simpler models and “verifiable data science”, e.g., intelligent defi with interactive LP rebalancing or credit scoring for lending protocols.
EZKL was built to scale to AI/ML workloads (and these applications are popular), but a ton of usage today is for verifiable data science.
Benefits
Doesn’t require trusting hardware manufacturer: Instead, purely trust software and cryptographic guarantees of correct inference.
Accessibility: Proving happens on generalized hardware, which is typically cheaper and more available than specialized hardware like TEEs.
Simple and permissionless verification: Anyone can verify the ZKP (which proves integrity during inference) and verification is typically much less resource-intensive than re-executing.
Downsides
High computational overhead associated with proving (100-10,000x compared to naive execution). Proving performance (time and cost) primarily depends on model complexity and the hardware used (consumer hardware vs servers). While inference of LLM-level models is theoretically feasible, it’s still prohibitively expensive and slow in practice:
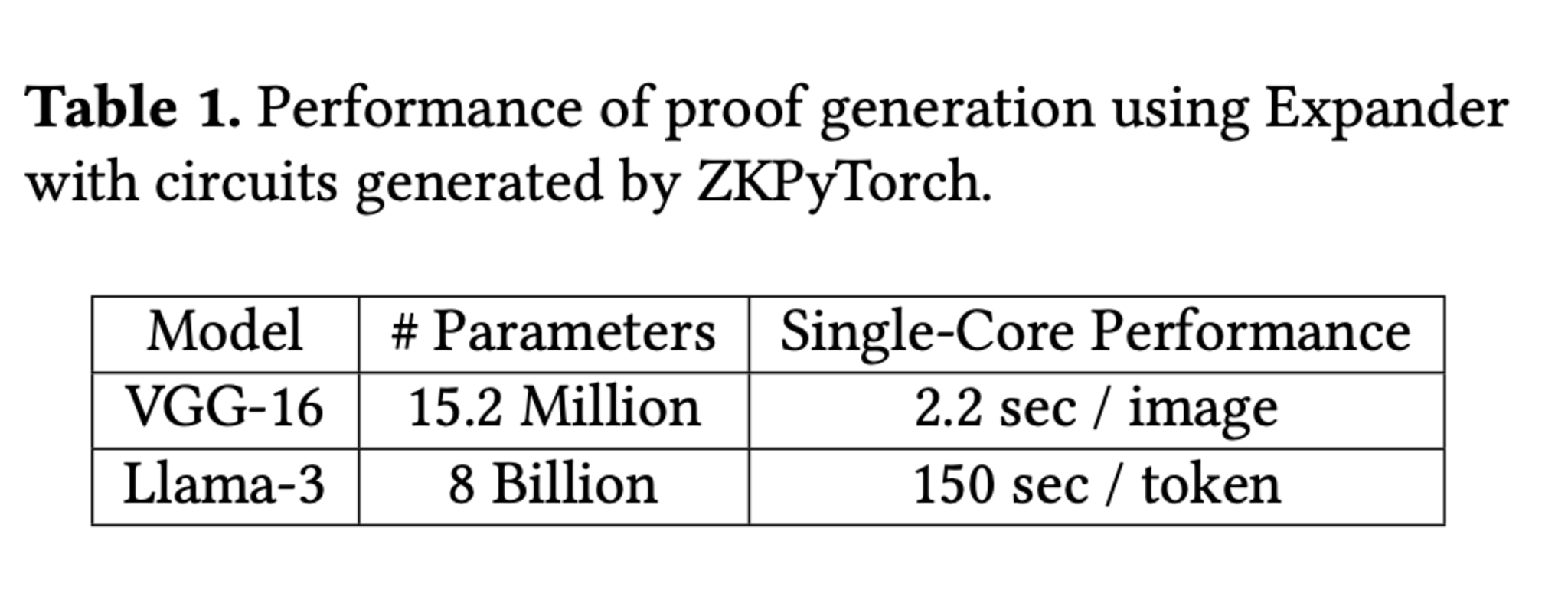
Benchmarks from Polyhedra show that proving a typical inference (50-100 tokens) of an 8 billion Llama3 model takes ~2-4 hours with their zkPyTorch framework (single CPU) (source)
Doesn’t Support Floating Point Arithmetic: Most current ZK proving systems work over finite fields and are designed around arithmetic circuits, and hence not tailored to prove native floating point arithmetic operations. This makes it challenging to prove highly optimized AI workflows, adding overhead.
Open Problems
Reducing the proving overhead to make ZK-based inference more feasible. This can happen through three main ways:
Software optimization: Developing ZK schemes optimised for certain types of models (or even a specific model).
Hardware acceleration: Specialized hardware that accelerates operations specific to proof generation (or even zkML). However, this is challenging as both ZKP and AI are still advancing so rapidly (risk of hardware becoming outdated too quickly for the investment in hardware to be worthwhile).
ZK evolves faster than model complexity grows: This would enable hardware and proof systems to catch up and improve relative to state-of-the-art models.
Ensuring robustness of ZK proving systems. Given the pace at which proving systems are evolving, the risk of bugs and exploitation (generating false proofs) is still relatively high. In the case of verifiable inference, this means:
Generating a proof that the correct model was used when in reality another, cheaper model was used (pocketing the difference).
Trying to hide interference with the process, for example by modifying the prompt before inference or inserting bias into the model.
More extensive model support at the compiler level: This is primarily a devex-related issue, but essential for adoption since most AI engineers are not ZK-experts. Hence, the process of translating AI/ML models into zk-circuits and generating proofs needs to be as seamless as possible, with support for a broad range of models.
Convincing users that ZKPs work: ZK is still a nascent technology and many users are sceptical about its benefits and the strength of guarantees it can provide. It’s possible that ZKP remains more of a B2B tech, but in consumer-facing products, the trust needs to be built case-by-case (e.g. through education, built-in verification, or visual cues like the padlock representing HTTPS in browsers).
Trusted Execution Environment (TeeML)
TEE is a hardware-based approach where inference happens inside a secure area of the processor. By isolating data and processing of sensitive programs (such as inference on personal data), unauthorized entities are unable to interfere with the process or modify the program.
Integrity during inference can be proved with a signature from the trusted hardware (“remote attestation”). While remote attestations don’t directly enable proving correct execution, they allow the TEE to convince a verifier that:
Software within the TEE hasn't been tampered with (code integrity)
Sensitive data (prompts and personal data) is protected during processing (data integrity)
Hardware and firmware remain uncompromised (hardware integrity)
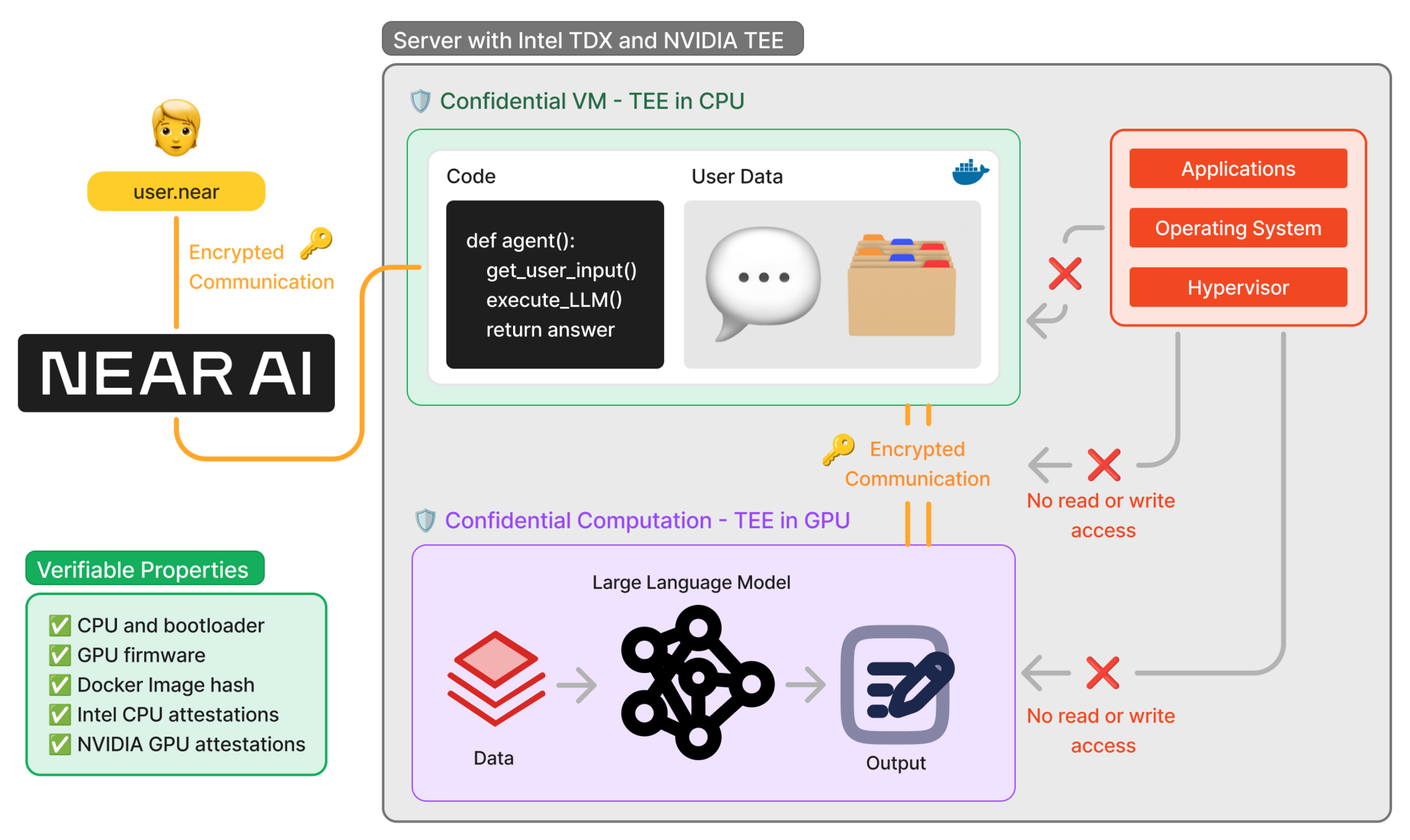
Source: Near AI
For easier and more permissionless verification, the attestation can be posted on a blockchain along with a verification program. Wrapping the remote attestation inside a ZKP would reduce the verification overhead, something that at least Risc Zero and Automata have explored (8x lower onchain verification cost).
Main Use Cases
Verifiable (and confidential) inference of large models (pragmatic solution due to low overhead).
Use cases that require both verification and confidentiality, but not as strong trust guarantees.
Agents and agentic workflows, with early experiments by Flashbots x Nous, Near (shade agents), and many more teams.
Web2 use cases that primarily require confidentiality (verifiability is a secondary benefit), like WhatsApp (processing on user chats), Tinfoil, and Privatemode AI.
Benefits
Low overhead: Compared to native execution, the overhead from running a computation inside TEEs is only ~5-10%. This offers a pragmatic approach to the verifiable inference of more complex models, such as state-of-the-art LLMs and other generative AI models.
Overhead decreases as model size grows: This is due to the fact that the I/O overhead (encrypting data in and out of the TEE) becomes increasingly insignificant relative to the overall computation.
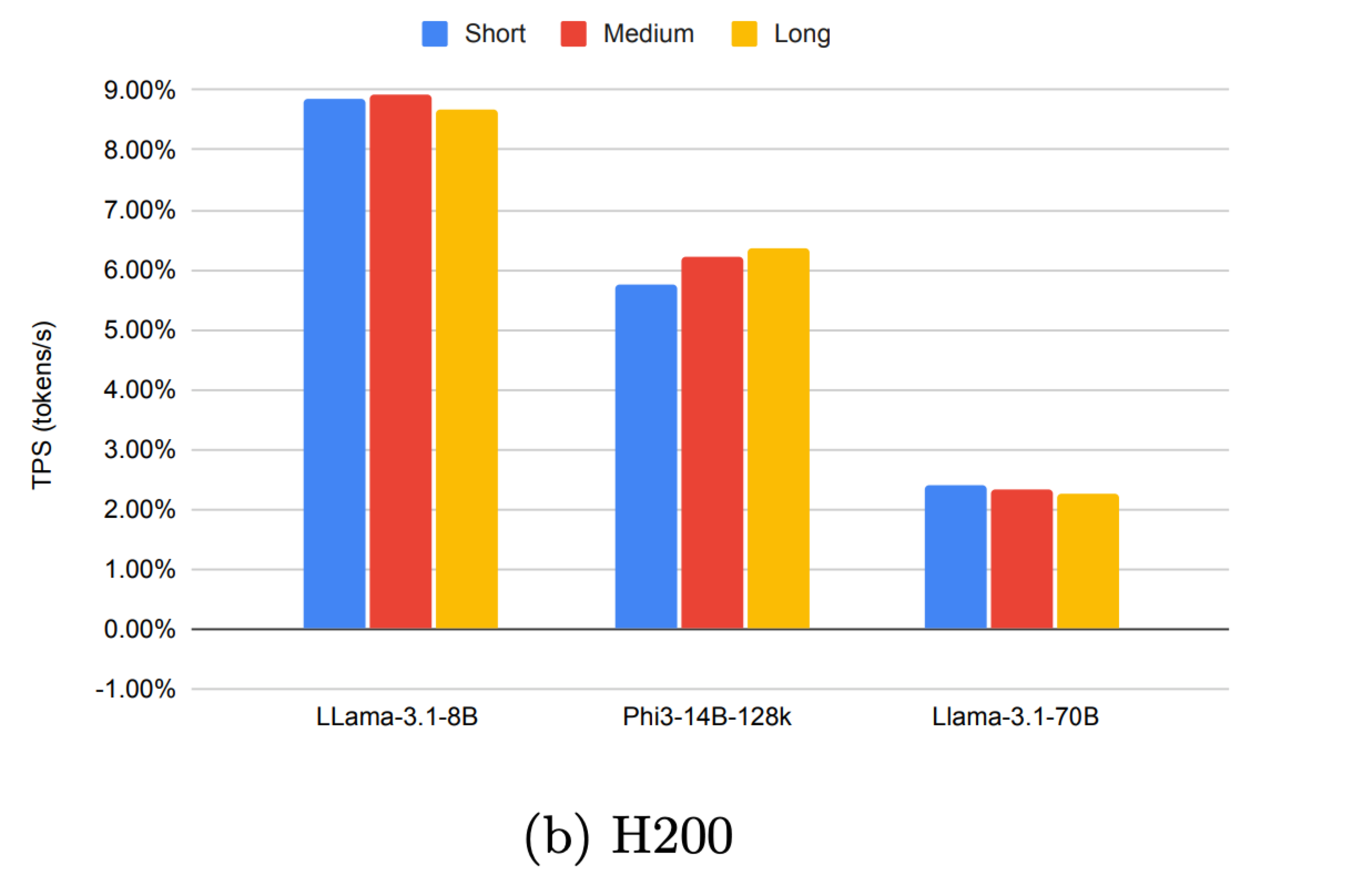
Source: Phala benchmarking report (focusing on NVIDIA H100 and H200)
Confidentiality: In addition to verifiability, TEEs provide some confidentiality guarantees by default, both in terms of data privacy (data remains encrypted outside the secure enclave) and model confidentiality (the developer doesn’t need to reveal weights, while still enabling others to run it). However, similar to attestations of computational integrity, the privacy guarantees require trusting the hardware manufacturer.
Downsides
Require trusting hardware manufacturers (Intel, NVIDIA…) that there are no backdoors or vulnerabilities in the hardware. While TEEs have several benefits, the guarantees don’t seem strong enough to secure or control billions of dollars on their own. For use cases that require strong guarantees, TEEs can be paired with cryptography (e.g. MPC) to increase robustness. For example, splitting the private key across multiple different nodes running on different hardware.
History of both physical and software-level attacks: These risks can be mitigated by pairing the TEE approach with MPC cryptography to split the workload across multiple nodes and using TEEs from different manufacturers (although this might raise compatibility issues).
Availability concerns: Trusted hardware is specialized and expensive, which can make it hard to come by. Modern GPUs are starting to have TEEs integrated (such as Nvidia H100/200), but organizations without access to the latest GPUs cannot leverage GPU TEEs until they upgrade or use a cloud that offers them.
Overall security of a combined GPU+CPU TEE system is only as strong as its individual components (e.g. Intel TDX and Nvidia H100). The CPU enclave protects orchestration and data preprocessing, while the GPU enclave protects heavy-duty ML compute.
Open Problems
Exploring edge cases and potential attack vectors: While TEEs are already used across a range of use cases in the “real” world, many blockchain use cases have even stronger security guarantees, making the consequences of a successful attack more devastating.
Hashing
Hashing is another software-based approach to verifiable inference, where cryptographic hashes are created from a model’s intermediate steps during inference. These hashes serve as commitments to the computation.
Verification by users or third-party auditors is enabled by computing the hashes of the intermediate activations and comparing them to the hashes provided by the compute providers (third party that did the inference). Hashing methods are often designed explicitly for LLMs, where the overhead from verifiability can be as low as a few percent due to the repeated computation being more efficient on GPUs. This is specific to the way that LLM inference works, where the generation is memory-bound while the validation can be compute-bound.
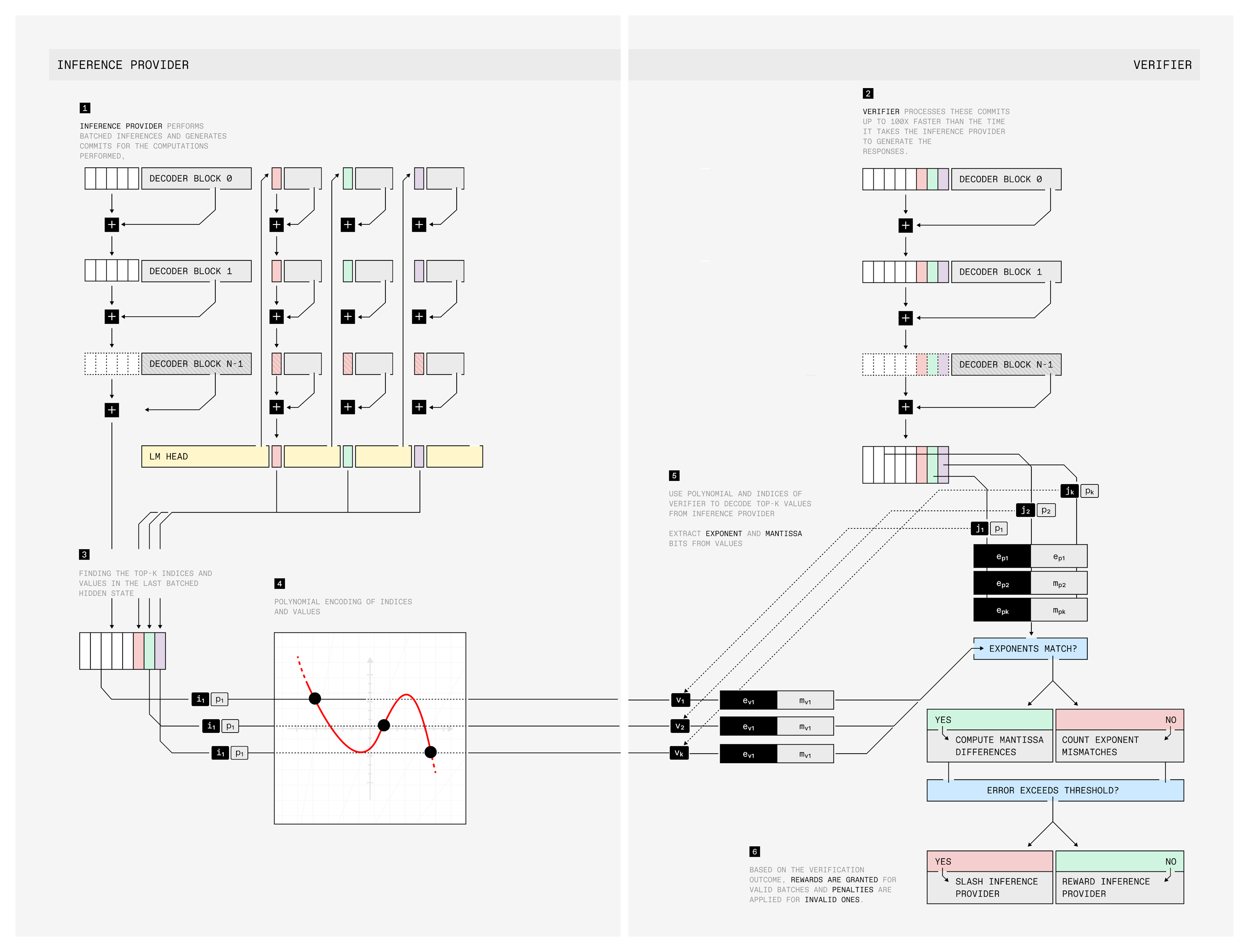
Overview of Prime Intellect’s TOPLOC hashing workflow (source)
Main Use Cases
Inference of large open-source models (LLMs) and low-impact queries that don’t require as strong guarantees
Decentralized training
Benefits
Low overhead: Generating the hash adds very little additional overhead, making it a feasible option for verifiable inference of large models. For LLMs, the overhead is in the range of 5-20% per validator (can be lower for non-LLM models).
Trustless verification (if the model is open source): External parties can verify the integrity of the computation if they have access to the model and weights. To verify the correctness, they recompute activations and compare the hash to the one provided by the inference provider.
Downsides
Hard to verify integrity with closed-source models: Verifying the hash requires the validator to be able to run the same model as the inference provider. For fully closed-source models, this would only be feasible through a TEE integration. While a hybrid solution could involve the model owner sharing part of the model (e.g. intermediate layers) to allow verification, this would only enable validating the part that was shared (and if done at random, the public could eventually piece together the model). In addition, the large closed-source AI companies seem adamant about not leaking their architecture and weights, making the hybrid approach unlikely.
Probabilistic guarantees: Hashing relies on statistical guarantees (how well the hashes match), which can lead to false negatives and potential edge cases. One example here is Mixture of Experts (MoE) models, where tokens are routed to multiple different specialized models (linear layers). Deviations and randomness can affect the routing, significantly impacting the final activations. This makes hash-based verification challenging.
Limited scope: Most approaches that use hashing algorithms for verifiable inference are tailor-made for text-based LLMs. There is active work to extend these methods to other types of models, but limited evidence of their efficiency.
Open Problems
Extending existing hashing implementations that are designed for LLM-based inference to other types of models (e.g. diffusion and image generation models).
Proving the empirical accuracy of existing implementations across a broader range of use cases, models, and inference requests.
Optimistic Verification (OPML)
Optimistic verification relies on game theory, economic incentives (rewards and slashing), and the presence of at least one honest watcher who can challenge the result if they suspect malicious behaviour. This is similar to the security model of optimistic rollups.
While this sounds simple in theory, the fraud-proof mechanism adds complexity (required to challenge results and solve disputes). In addition, the optimistic approach to verification requires a sufficiently long challenge period to allow watcher nodes enough time to verify the computation, thereby delaying the finality of the results.
Main use cases
Latency-insensitive applications that don’t require as strong guarantees around verifiability
Verification of deterministic and open-source models
Benefits
Low overhead: The only additional cost comes from re-execution (watcher nodes that re-run the computation and compare results) and potential challenges, which limits the total overhead. Potential chain reorgs would also introduce additional complexity, but these are rare and the impact is hard to reason about.
Downsides
Only works for deterministic computation, where the same input always yields a comparable output. This means that optimistic verification is not reliable for non-deterministic models (e.g. generative AI models) and makes it difficult to prove malicious intent. Tricks such as the likeness of answers (both “Paris” and “the capital of France is Paris” are correct answers to the prompt “what is the capital of France?”) aim to mitigate this challenge, but only cover limited use cases and models.
Delayed finality, since the results depend on the length of the challenge window, which can be days or weeks. This makes the optimistic approach an impractical solution for any use case that is latency sensitive.
Open Problems
Tradeoff between security and the lenght of challenge period: The longer the challenge period, the longer the delay to finality. However, if the challenge period is too short, there is a risk that a verifier doesn’t have enough time to re-execute and potentially raise a challenge.
Random Sampling
Similar to OPML, random sampling relies on re-execution to verify integrity. It can be interpreted in two ways:
Inference requests are verified only at random intervals: By spreading out verification at random intervals and having a sufficiently large punishment for misbehaviour, inference providers are incentivized to behave honestly. Besides simple re-execution from the watcher node(s), it’s possible that TEE attestations or ZKPs could be used to strengthen guarantees of each random sample (if set up beforehand).
Small subset of nodes chosen for a specific computation: Rather than all nodes re-executing all computation, a small subset of nodes is chosen for a specific computation. If all are in agreement about the output, then that becomes the final result. Otherwise, the result is determined by some form of consensus (e.g., the result of ⅔ of nodes) or external dispute resolution. Economic rewards and slashing can be used to incentivise good behaviour and deter malicious work.
In practice, these two methods can be combined to minimize overhead.
Main use cases
Verification of deterministic and open-source models
Benefits
Limited overhead: The extra computation comes from re-execution (and potential consensus overhead), which can be controlled depending on the redundancy required.
Downsides
Only works for deterministic computation: Similar to optimistic verification, random sampling relies on two or more nodes being able to arrive at the same output, given the same model and input.
Industry Overview
By now, there are multiple companies working on different parts of the problem space. Below is a summary along with links for further reading:
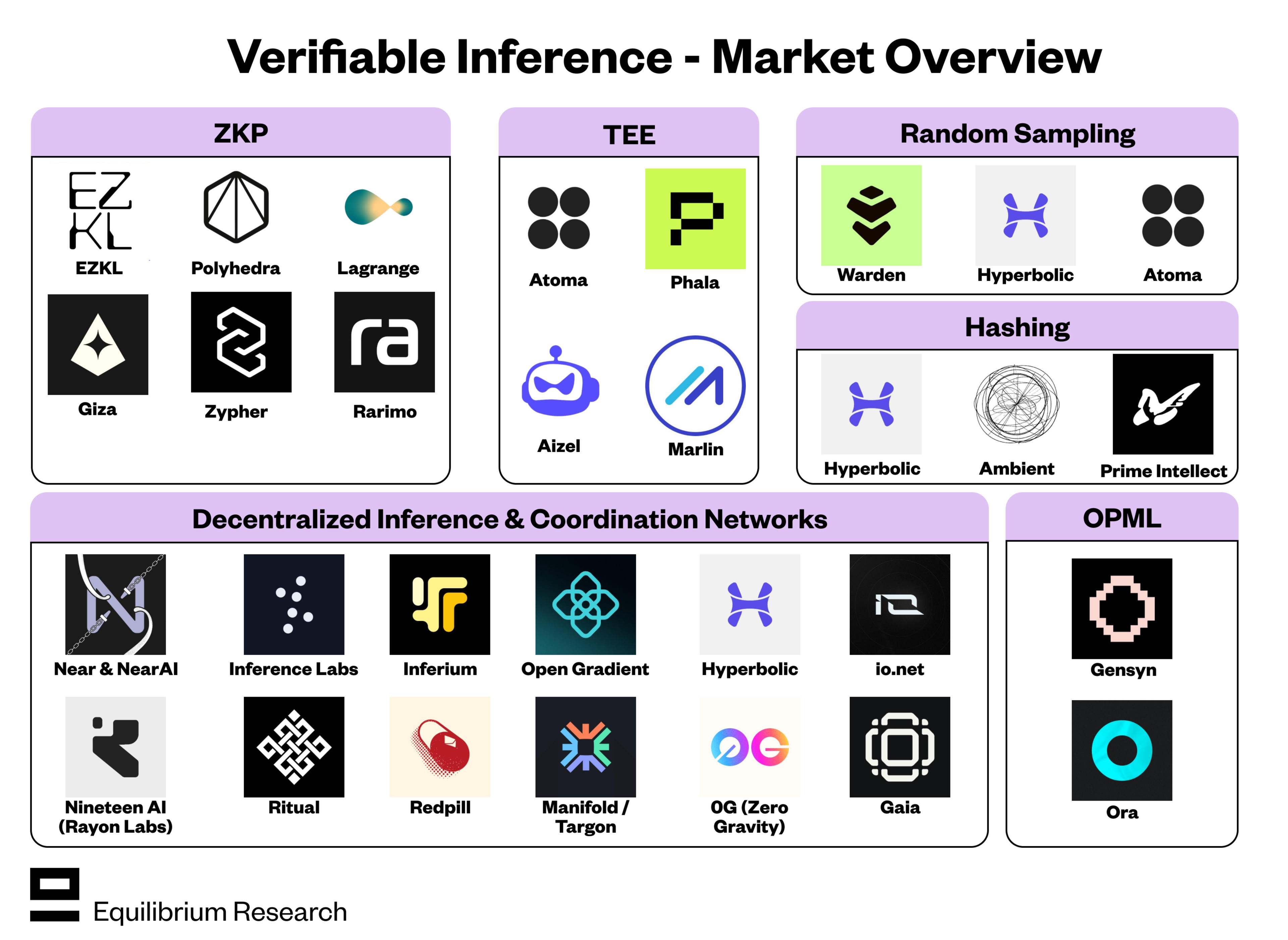
ZKP
EZKL: Provides compute for verifiable AI (inference) and analytics products along with a compiler framework to convert models into ZK circuits (works for any model compatible with the ONNX standard). Initially built for zkML, but most of the demand today comes from verifiable data science. Used by a wide range of DeFi protocols (Balancer, QuantAMM,..), L2s (Optimism), and decentralized inference networks such as Inference Labs. More recently, the team has also been focusing on cosnarks to allow two parties (model owner and data owner) to jointly generate ZKP without revealing confidential information to each other. The implementation leans on Renegade’s 2PC-optimized MPC library.
Giza: Provides infrastructure for autonomous DeFi agents, leveraging ZKP for proving correct inference of certain strategies. The models used are relatively simple, such as trend classification for automated LP management. Deployed on Starknet, leveraging the STWO prover for proof generation and the Herodotus Atlantic API for verification.
Lagrange: The DeepProve library provides a compiler framework that supports converting ONNX-based AI models into ZK circuits and proving integrity during inference. Lagrange also provides compute resources through their prover network for outsourcing proof generation.
Polyhedra: The zkPyTorch compiler framework supports converting PyTorch and ONNX models into verifiable ZK circuits. On the backend, it leverages Polyhedra’s proof system Expander, while their proving network ProofCloud is used for outsourced computation and proof generation. The team is currently working on GPU compatibility for the prover.
Rarimo: The Bionetta proving framework is tailored for proving and verification on consumer devices, particularly smartphones. The primary use case of Bionetta is for ZK-proving a face recognition model, which is a crucial part of their zkPassport product and other identity solutions (prove that you are the same person as the one in the passport). The model and weights are public, but keeping user inputs private is paramount. By focusing on local inference and client-side proving, Rarimo can provide strong privacy guarantees for users.
Zypher Network: Primarily focuses on building infrastructure for onchain gaming and onchain agents. Zypher splits proving integrity into proof of inference (ensuring that AI Agents strictly adhere to predefined rules or AI model operations) and proof of prompt (proving the consistency of model behavior), but the core idea is the same.
TEE
Aizel Network: TEE-based verifiable inference infrastructure for state-of-the-art LLMs, AI agent infrastructure, and smaller models (e.g. face recognition). Splits the architecture into four parts: gate nodes (receive user requests and assign inference tasks to appropriate inference nodes), data nodes (store models and other information), inference nodes (perform the actual inference tasks), and verifier nodes (validate remote attestations). Still under development and some of the code is not open-source, but existing partnerships include Peaq, Avalanche, Mode, Virtuals, and more.
Atoma Network: Offers TEE-nodes for verifiable (and confidential) inference, in addition to random sampling (more below). Currently, there are three models deployed (Llama 3.3 70B, Mistral Nemo, and DeepSeek V3) with 6 nodes across all networks, so the network implementation is still relatively early stage.
Marlin Protocol: A confidential compute marketplace that provides the infrastructure to host apps on both CPU and GPU TEEs through their coprocessor Oyster. These can be used for training AI models and verifiable inference, among other use cases. Users can choose from more than 140 compute providers across 25+ countries. Marlin also enables wrapping the attestation in a ZKP for easier and cheaper onchain verification (proof generation takes ~15mins).
Phala Network: Phala Cloud (built on Dstack) provides a low-cost and user-friendly environment for hosting AI agents, LLM inference, and training in CPU and GPU TEEs. The private-ml-sdk framework (granted by NEAR AI and built by Phala) provides the infrastructure to deploy and run LLMs securely within GPU TEEs. This includes a secure execution environment, remote attestation (verification), secure communication between the user and LLM, and a key management service. Active partnerships with Near AI, 0G, Hyperbolic, and more.
Hashing
Ambient: A POW-based SVM fork that is focused on running a single, 600bn parameter model. Proving the integrity of inference (miners running the correct model) through Proof of Logits (PoL), which is a form of model “fingerprinting” based on logits (raw numerical outputs). Validators can verify individual tokens and the mathematical relationships between them at random points, rather than having to replicate the entire inference process. Claims to achieve only 0.1% overhead, but details are sparse and there is no open-source implementation yet.
Hyperbolic: An open-source inference and compute network, which has also developed a couple of solutions to verifiable inference. One of these is SVIP, which is a hashing-based approach to verifiable LLM inference that leverages intermediate outputs (hidden states) of the LLM as unique model identifiers. A separate proxy model is trained exclusively on the hidden states from a specific model (e.g. Llama3.1 70bn) and used to verify whether the claimed model was used. Empirical testing shows that SVIP achieves false negative rates below 5% and false positive rates below 3%, but it requires fixed-length inputs and was only tested on prompts between 5 and 48 tokens long. In addition, parts of the proxy model need to remain hidden from the inference provider.
Prime Intellect: Toploc is a hash-based framework for verifiable inference that works for text-based LLMs (with attempts to extend the framework to further models). During inference, the service provider commits to the top-k values in the last hidden state, which can later be verified by the validator by recomputing the last hidden states (limits overhead to ~1%). While initial empirical evaluations show that Toploc can detect unauthorized modifications to models, prompts, or compute precision with ~100% accuracy, hashing can only provide statistical guarantees and there is a risk of edge cases that weren’t tested for. Toploc is only one component of Prime Intellect’s broader offering, which includes both decentralized training and inference.
Optimistic Verification (OPML)
Gensyn: While Gensyn primarily focuses on decentralized training and fine-tuning of AI models, they have also developed a verifiable inference protocol called Verde. It uses an optimistic design and relies on the existence of at least one honest party. Computation is split into steps to limit the dispute (don’t need to rerun the entire task). This could potentially also apply to verifiable inference, not just training.
Ora: Enables optimistic verification of AI inference, where the result is posted onchain with a challenge period. During this time, opML validators can verify the result, and if found to be incorrect, submit a fraud proof. The correct result replaces the original one.
Random Sampling
Atoma Network: In addition to their TEE approach, Atoma also offers random sampling for verifiable inference on hardware that doesn’t support TEE. In this case, at least two nodes run the same computation (inference) and compare results. The user can determine the amount of redundancy they want, i.e. the number of nodes that re-execute. Cross-validation sampling takes this a step further and only requires nodes to re-execute at random intervals, reducing the overhead but providing weaker guarantees.
Hyperbolic: In addition to the hashing approach (SVIP), Hyperbolic has also developed a scheme called Proof of Sampling which randomly verifies a subset of all inference requests. A second independent node runs the same computation and can trigger arbitration if it finds the original node has misbehaved. Low overhead, but limited strength of guarantees.
Warden Protocol: With SPEX (Statistical Proof of Execution), verifiers check a subset of intermediate and end results through re-execution and compare whether their results match. However, this approach struggles with non-deterministic computation, similar to OPML.
Decentralized Inference and Coordination Networks
Decentralized inference includes outsourcing inference to a geographically diversified network of untrusted compute providers. The integration is permissionless, meaning anyone with the required compute power can join the network (as opposed to distributed inference networks, where only whitelisted actors are allowed to join). Decentralized inference networks can improve:
Censorship resistance - Enabling users around the world to have equal access to the technology.
Liveness - The system keeps working even in the case of local failure, e.g., due to node malfunction.
Cost of inference - Tapping into latent hardware and compute capacity.
Most decentralized inference and coordination networks leverage existing verifiable inference techniques (often more than one), rather than developing their own. Companies in this space include (excluding those that have no verification of integrity during inference):
Near & Near AI: Aiming to build an end-to-end process for confidential, user-owned AI, particularly focusing on agentic workflows and state-of-the-art generative AI models. Leverages TEEs for inference, focusing on both verifiability and privacy guarantees. Private-ml-sdk is a secure and verifiable solution for running LLMs in TEEs, developed in collaboration with Phala Network. It enables leveraging the latest NVIDIA TEE GPUs (H100/H200/B100) and has Intel TDX support.
Inference Labs: Omron is a Bittensor subnet developed by Inference Labs that aims to be the coordination network for proving and verifying inference within the Bittensor ecosystem. Other subnets or third parties can integrate their own ZK circuits into the Omron subnet. Inference Labs primarily uses EZKL tech stack for turning models into ZK circuits and proving, but seems to be working to diversify to other providers (e.g. recent partnerships with Lagrange).
Open Gradient: An L1 built for full-stack AI use cases. On the verifiable inference side, they are agnostic to different solutions, instead letting developers and users choose the most suitable method for their use case (tradeoff between speed, cost, and security). Offers ZKML, TeeML, OPML, and vanilla inference (no verification).
Hyperbolic: Compute (GPU) marketplace and coordination network for AI inference and training jobs, with a range of available models. Verification of correct inference is through Proof of Sampling (randomly re-runs and verifies a subset of all inference requests) or hashing (SVIP). Doesn’t enable privacy-preserving inference.
Inferium: Provides Inference-as-a-Service, with both ZKP and TEE offered for verifying correct inference. ZKP is used for smaller models, while larger models use TEE. Leverages existing compute providers, such as Marlin for TEE.
Targon: Bittensor subnet focusing on inference, which leverages TEEs for confidential and verifiable inference. The roadmap includes expanding to secure, decentralized training with confidential compute.
Nineteen AI: Bittensor subnet focused on decentralized inference, primarily for image generation models. Miners (compute providers) host multiple models that users can choose from. Verifiability through random sampling and economic security, where validators check and score the miners through "checking servers" that they run on their own hardware.
Ritual: An incentive and coordination layer for decentralized inference. Takes a modular approach to verifiable inference and computational integrity, where developers and users can choose between ZKML, TeeML, and OPML (depending on their needs).
Redpill: A model aggregator and inference provider. Redpill provides outsourced inference for more than 200 different models, but only a few of them are hosted on GPU TEEs for verifiability and confidentiality (leverage Phala’s infrastructure). Those models have been integrated with Openrouter.
0G: Inference marketplace that aims to support a range of models with methods for verifiable inference. For now, only TeeML is available (leverages Phala’s infrastructure), but options for OPML, TeeML, and ZKML are coming later. In addition to verifiable inference (and broader AI compute services), 0G is also building a DA and storage solution.
io.net: A GPU marketplace and coordination network, which can be used for hosting AI models and inference (among many other things). Partners with Marlin and Phala (at least) to include TEE-GPUs in their offering and enable verifiable and confidential inference.
Gaia: Focuses on building a platform for scaling and monetizing AI agents, a part of which is the decentralized inference network. Gaia offers ZK-based verification of integrity during inference, through a partnership with Lagrange.
Future Directions - Where Is Verifiable Inference Heading?
We expect the demand for verifiable inference to grow by several orders of magnitude from today, primarily due to three main drivers:
Deteriorating Trust In Big Tech: Scepticism against Eastern tech companies (e.g. TikTok or Alibaba) is already becoming quite widespread in the West, but there are also signs of American tech giants losing trust amongst users. While the average user today still trusts OpenAI and Google enough to outsource inference requests to them (800mn and 400mn active users respectively), this might change as users become more educated about the risks involved and as AI models become a more integral part of our lives.
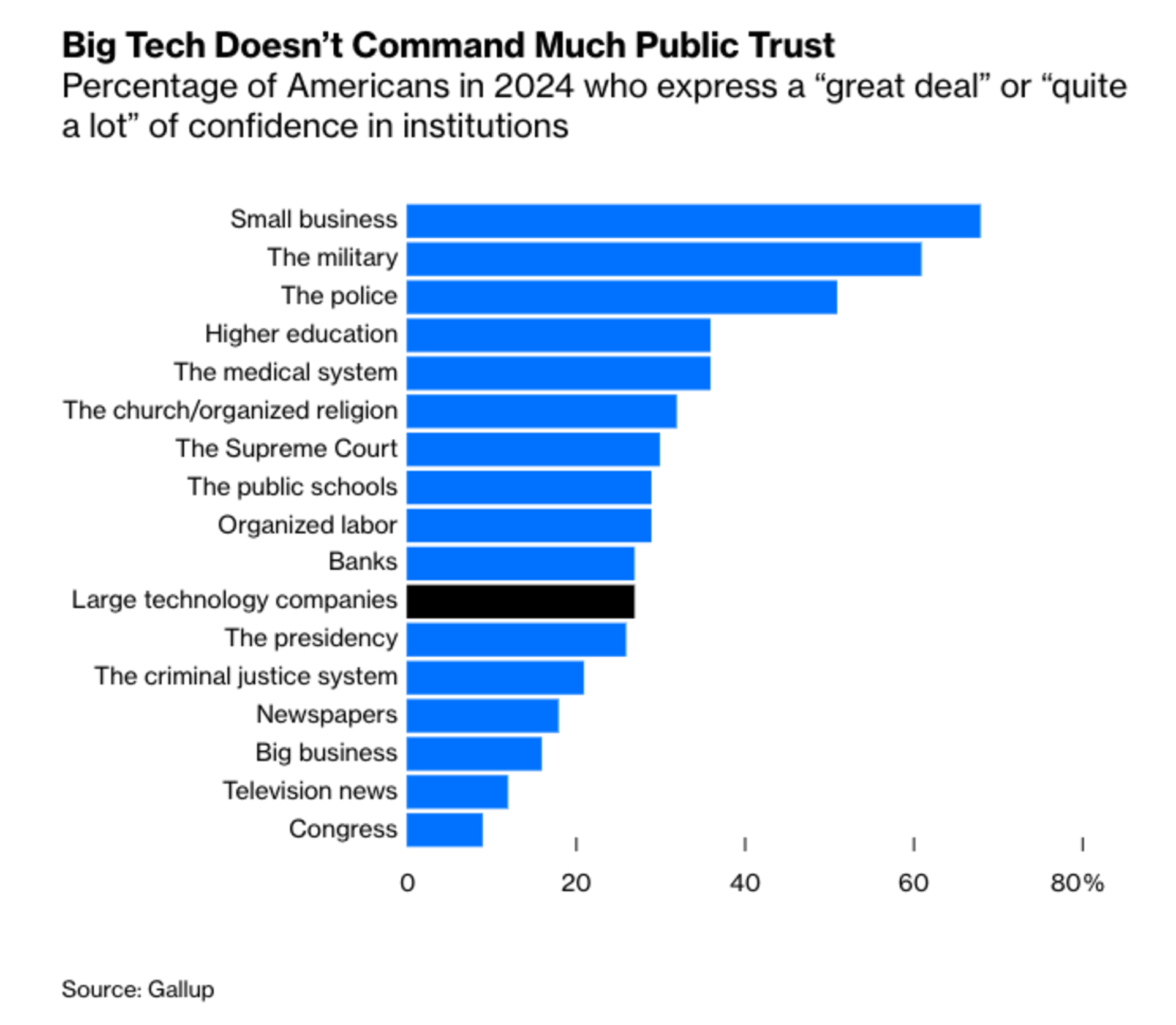
Source: Gallup
Broader Integration Of AI Into Critical Workflows: The margin for error in critical workflows, such as medical diagnostics or financial analysis, is low. As these integrate AI to an increasing degree, it’s reasonable to assume that they have a greater willingness to pay a bit extra for guarantees of integrity and traceability (compliance and limiting personal liability).
Expanding Onchain Use Cases: Verifiable inference is a prerequisite for anyone serious about integrating AI into onchain applications. We believe the drivers here will be twofold:
Onchain applications (both existing and new) leverage AI to an increasing degree. This increases demand for verifiable inference even if the user base stays constant.
Onchain usage expands, driven by new use cases, better infrastructure, and smoother UX. If onchain applications that leverage AI receive at least a share of this growth in user base, that increases the overall demand for verifiable inference.
While the larger vision is similar for most projects - proving integrity during inference to increase trust, improve auditability, and enable decentralized inference - practical implementations today already differ. We expect protocols to further capitalize on their strengths as the market continues to grow (enough room to specialize). Ultimately, each use case needs to be evaluated separately to find the right tradeoffs.
zkML is primarily used for proving simple models in use cases where integrity is paramount, such as DeFi and identity-related solutions. We expect these to be the core drivers in the future as well, where strong verifiability guarantees far outweigh the proving overhead.
TEEs are best suited for complex agentic workflows and frontier generative AI models, since proving integrity here is resource-intensive and may require additional confidentiality guarantees. For onchain use cases that require stronger guarantees, expect to see more experimentation around MPC x TEE to increase robustness.
Hashing-based approaches are also well suited for low-impact, resource-intensive proving (e.g. LLM inference) that don’t require confidentiality from the service provider.
Optimistic and sampling based solutions may struggle to find real-world use cases (either in web2 or web3). They can neither offer the strongest guarantees nor the lowest overhead, only work for determinstic and open-source models, and don't provide any additional guarantees around confidentiality.
Continue reading

July 10, 2026
Harvest now, forge at Q-day: the quantum clock is already running for blockchains
We reviewed the node implementations of the 36 largest blockchains. Two have any post-quantum code; none protect consensus. Why exposed public keys make the quantum threat a today problem, not a Q-day one.

April 21, 2026
ZAIR: Zero-Knowledge Selective Disclosure for Zcash Notes
Imagine proving you hold Zcash without revealing which note, how much, or anything else. That's no longer hypothetical. Here's how we built the first end-to-end selective disclosure tool for Sapling and Orchard

April 9, 2026
Scaling distributed systems: Eiger and Equilibrium Labs unite
we're excited to announce that Eiger and Equilibrium Labs are merging to form Equilibrium —a unified team dedicated to advancing the infrastructure that powers the decentralized web.

March 25, 2025
Introducing Our Entrepreneur in Residence (EIR) Program
After 6+ years of building core blockchain infrastructure across most ecosystems and incubating ventures like ZkCloud, we're looking for ambitious pre-founders with whom to collaborate closely.

March 10, 2025
From Speculation to Utility: Next Steps For Onchain Lending Markets
Despite its promises, onchain lending still mostly caters to crypto-natives and provides little utility besides speculation. This post explores a path to gradually move to more productive use cases, low-hanging fruit, and challenges we might face.

February 18, 2025
Can Blockchains And Cryptography Solve The Authenticity Challenge?
As gen-AI models improve, it's becoming increasingly difficult to differentiate between AI- and human-generated content. This piece dives into whether cryptography and blockchains can solve the authenticity challenge and help restore trust on the Internet

February 6, 2025
Vertical Integration for both Ethereum and ETH the Asset
In recent months, lackadaisical price action and usage growing on other L1/L2s has driven a discussion on what Ethereum’s role and the value of ETH, the asset is long-term.

January 29, 2025
Equilibrium: Building and Funding Core Infrastructure For The Decentralized Web
Combining Labs (our R&D studio) and Ventures (our early-stage venture fund) under one unified brand, Equilibrium, enables us to provide more comprehensive support to early-stage builders and double down on our core mission of building the decentralized web

November 28, 2024
20 Predictions For 2025
For the first time, we are publishing our annual predictions for what will happen by the end of next year and where the industry is headed. Joint work between the two arms of Equilibrium - Engineering and Ventures.

November 7, 2024
9 + 1 Open Problems In The Privacy Space
In the third (and final) part of our privacy series, we explore nine open engineering problems in the blockchain privacy space in addition to touching on the social/regulatory challenges.

October 15, 2024
Aleo Mainnet Launch: Reflecting On The Journey So Far, Our Contributions And Path Ahead
Equilibrium started working with Aleo back in 2020 when ZKPs were still mostly a theoretical concept and programmable privacy in blockchains was in its infancy. Following Aleo's mainnet launch, we reflect on our journey and highlight key contributions.

August 12, 2024
Do All Roads Lead To MPC? Exploring The End-Game For Privacy Infrastructure
This post argues that the end-game for privacy infra falls back to the trust assumptions of MPC, if we want to avoid single points of failure. We explore the maturity of MPC & its trust assumptions, highlight alternative approaches, and compare tradeoffs.

August 1, 2024
Working on Aptos: Insights into Mutation Testing and Specification Assurance

July 23, 2024
Equilibrium brings Move to Polkadot

July 23, 2024
Releasing Lumina.rs - Directly verify Celestia in your browser
We're excited to release Lumina. Go to https://lumina.rs/ and run a Celestia light node in the browser. By running Lumina you synchronize with the network, sample data availability, directly verify correctness and contribute to the network health

June 12, 2024
What Do We Actually Mean When We Talk About Privacy In Blockchain Networks (And Why Is It Hard To Achieve)?
An attempt to define what we mean by privacy, exploring how and why privacy in blockchain networks differs from web2, and why it's more difficult to achieve. We also provide a framework to evaluate different approaches for achieveing privacy in blockchain.

April 9, 2024
Will ZK Eat The Modular Stack?
Modularity enables faster experimentation along the tradeoff-frontier, wheras ZK provides stronger guarantees. While both of these are interesting to study on their own, this post explores the cross-over between the two.

January 16, 2024
Nebula for Soroban: Simplifying Contract Execution

January 16, 2024
Equilibrium is taking over responsibility for Beerus StarkNet Light Client

December 14, 2023
Enhancing Rust RPC Client and Nodes for Celestia Network

December 11, 2023
Introducing the MoveVM Substrate Pallet

October 23, 2023
Unveiling the Zcash UniFFI Library

October 5, 2023
Overview of Privacy Blockchains & Deep Dive Of Aleo
Programmable privacy in blockchains is an emergent theme. This post covers what privacy in blockchains entail, why most blockchains today are still transparent and more. We also provide a deepdive into Aleo - one of the pioneers of programmable privacy!

September 18, 2023
Securing cross-chain communication from Ethereum to the Internet Computer with an on-chain Light Client

September 4, 2023
Elusiv: Bringing Privacy To Solana

July 31, 2023
Engineers thoughts: Fireblocks SI partnership

July 25, 2023
Introducing OpEVM: The Next Generation Optimistic EVM Rollup

June 7, 2023
Equilibrium Becomes the First Accredited Systems Integrator for Fireblocks
March 12, 2023
2022 Year In Review
If you’re reading this, you already know that 2022 was a tumultuous year for the blockchain industry, and we see little value in rehashing it. But you probably also agree with us that despite many challenges, there’s been a tremendous amount of progress.

May 31, 2022
Testing the Zcash Network
In early March of 2021, a small team from Equilibrium applied for a grant to build a network test suite for Zcash nodes we named Ziggurat.

June 30, 2021
Connecting Rust and IPFS
A Rust implementation of the InterPlanetary FileSystem for high performance or resource constrained environments. Includes a blockstore, a libp2p integration which includes DHT contentdiscovery and pubsub support, and HTTP API bindings.
June 13, 2021
Rebranding Equilibrium
A look back at how we put together the Equilibrium 2.0 brand over four months in 2021 and found ourselves in brutalist digital zen gardens.
January 20, 2021
2021 Year In Review
It's been quite a year in the blockchain sphere. It's also been quite a year for Equilibrium and I thought I'd recap everything that has happened in the company with a "Year In Review" post.